大概是微博这个东西刚刚流行起来之时,也就是我初中的时候,我便用心的经营着我的腾讯微博,倒不是想要成为微博大咖,只是认为在同龄人坐在电脑前都只会打游戏时,我刷刷微博、发表一下自己的看法和见解,是更有意思的一件事。
然而腾讯微博迅速就被新浪微博超越,市场占有率几乎为 0 了。我自然也投靠了人多势众的新浪微博,但之前在腾讯微博中发的超过 1000 条微博是我的回忆 —— 中二青春。
我有一种预感,过不了多久腾讯微博就要被腾讯关停了,我可不能让之前写的那些碎碎念就这么消失,于是我用 Python 写了一个爬虫,将所有 [微博+图片+时间+转发微博+转发微博的所有信息] 都给爬到了本地数据库中,然后使用 React 做成了一个网站,名曰“复刻版腾讯微博”,将我发的微博放心地永远留在了自己的服务器中。
查看我的腾讯微博复刻网站,请点击:


截至目前,我的腾讯微博上共 1661 条微博,收听 65 人,听众 765 人。然而爬虫运行完毕之后获取到的微博数量为 1620,另外 41 条数据不翼而飞。我发布的微博和转发的微博中共包含了 1220 张图片,其中 6 张已被他们服务器丢失。微博中共包含 98 个视频,其中的 88 个均丢失(这是视频网站的锅,我们上传到优酷上的视频真的会被他们永远存放着吗,想想也是不可能的)。
微博中还包括了 785 条诸如 http://url.cn/482SZS 这样的短链接,其中 90% 均已失效,访问时直接提示 您访问的网址有误或该网址已过期 :( 此外,虽然 2011 年的微博也还给我留着,但所有微博的评论均没有了,数据被删掉了。。。
我想说的是,要是再不使用爬虫将这些宝贵的回忆取回,真说不定哪天就被腾讯给删掉了 ToT
讲真,各种复杂的情况都被我遇到了: 微博不提供 API,使用 Python 爬取 HTML 再解析,关键是 HTML 结构每次都会变,我花了很久很久的时间才适配了所有情况。另外服务器返回的数据并不可信,第一次得到的数据显示我在某一天发了 1 条微博,带有图片,再获取一次变成了发了 4 条,却无任何图片上传。(这不是腾讯为了防爬虫设计出来的,因为浏览器访问也是这样的,大概是腾讯微博在临死前,为了降低服务器负载而采用的拒绝式服务。。。)
于是我的爬虫在经过数天的完善后,拥有了应对前后数据不一致、连接握手失败、适应 HTTP 结构变化的功能。在此基础上又运行了四五天,才完成了爬取。因为对我那 1000 条微博的每一躺爬取,结果都是不一致的,直到最后连续运行十个小时也没爬出新数据后,我才认为是爬完了。
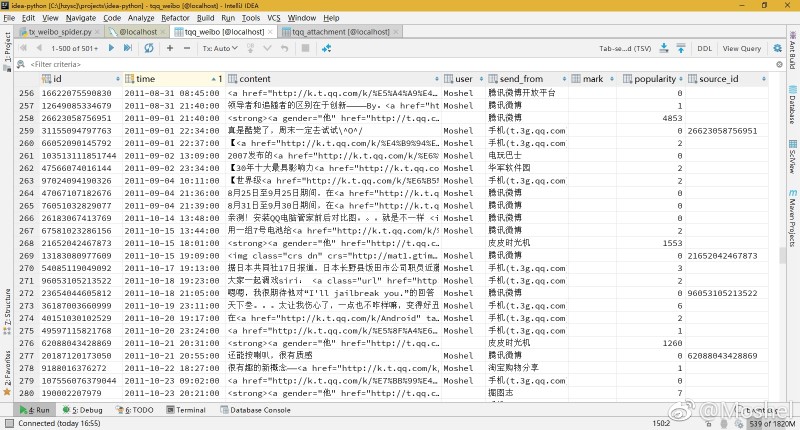
最终顺利爬取了能找到的所有数据,并存在了数据库里,真的是超级辛苦,让我激动的发了个微博(新浪微博~~)
数据清洗
数据清洗除了格式上的规范,还标记了一些重复的微博,这些微博在我的博客、空间里面重复,我的微博镜像站中没有必要包含这一部分内容。
此外为了制作微博镜像站,使用 Pillow 库将图片原图批量压缩成了 webp 格式的缩略图,在我的微博镜像站中,点击缩略图即可查看大图。 然而事实证明选择 webp 格式是错误的 ,虽然谷歌的 webp 格式拥有很高的压缩率,但是兼容性是个问题,不支持 Firefox、IE 和 iOS,几乎是只有 Chrome 能显示,所谓的 WebP JS 兼容性修复库其实是使用了 Flash 实现,然而后者本身就不值得使用。 所以说 WebP 格式的图片只适合客户端而不适合浏览器端。

最终我还是选择了 jpg 格式作为缩略图。毕竟我的服务器拥有 自动转换为 WebP 功能。
愉悦的 React 开发体验
感谢 facebook/create-react-app 提供的脚手架,webpack+eslint+react 开发环境开箱即用。另外不得不感叹 React 的模块化使得逻辑相当清晰,很方便省心。
另外还要感谢 clean-blog CSS 主题 和 lightgallery.js 图片灯箱插件
接下来
如果 QQ 空间、朋友圈、微博、豆瓣 这些网站在某一天宣布关停,我也会把自己的数据通通扒回本地,当我真心不希望这样,因为这个网站本身,就是一代回忆。
有空的话还要干几件事:试着统计下我发的微博中的一些有趣的数据,比如口头禅、文字情感之类的。再来就是把微博中的短链接替换成为长链接,因为正如上文提到的那样,很多短链接都在陆续失效了。
就酱。
现已完成,对我的腾讯微博的大数据统计挺有意思,请访问: https://hzy.pw/p/2569
azhfhk
hv2pvd